
官方网站咱们经常会使用很复杂的领导词模板-开")


IOI 2024 金牌开yun体育网,OpenAI o3 平缓高分拿下!
刚刚,OpenAI 发布了对于推理模子在竞技编程中哄骗的讨论论文回报,论文中放出了 OpenAI 家推理模子三兄弟在 IOI 和 CodeForce 上的具体得益。
三兄弟分辨是 OpenAI o1、o1-ioi(以 o1 为基础微调等翻新而来)、o3,三者得益如下。
IOI 2024,海外信息学奥林匹克竞赛:
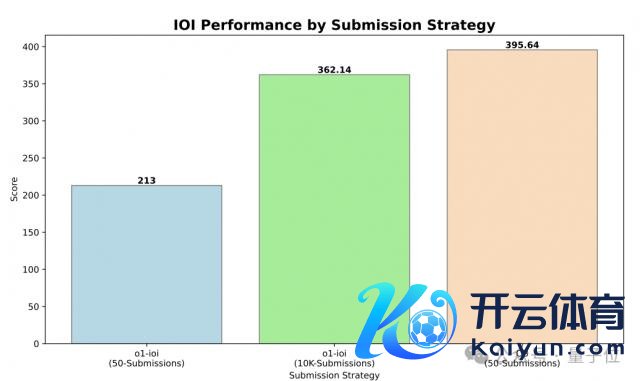
o1-ioi在严格划定下拿到 213 分(49th percentile),放宽提交戒指后飙升至 362.14 分;
o3在严格划定下就拿到了 395.64 分,终了金牌建立。
CodeForeces,模拟真确竞赛环境评估模子。
其中,o1-ioi 和 o3 的评分显耀高于 o1,尤其是 o3,还是接近顶级东谈主类选手:
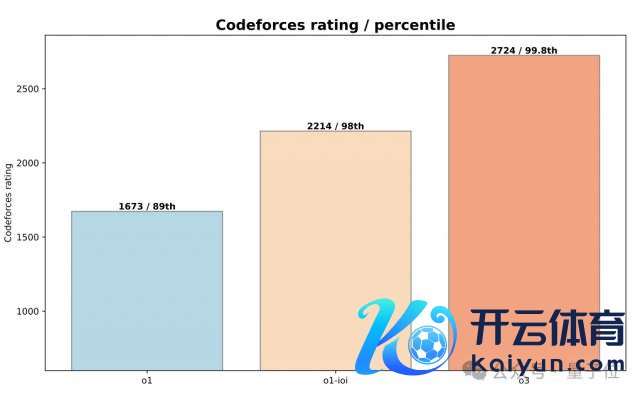
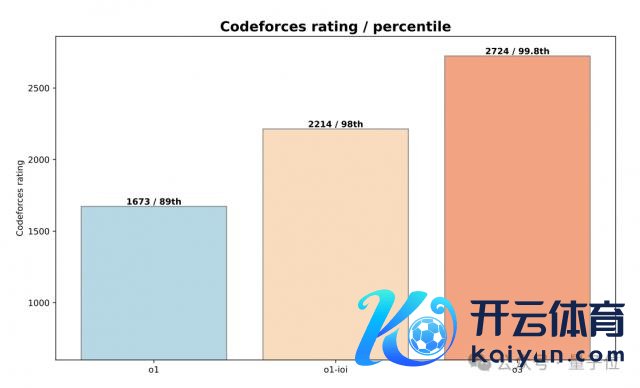
o1:1673(89th percentile)
o1-ioi:2214(98th percentile)
o3:2724(99.8th percentile)
论文马上在全网扩散开来,网友竞相传阅并热烈商讨。
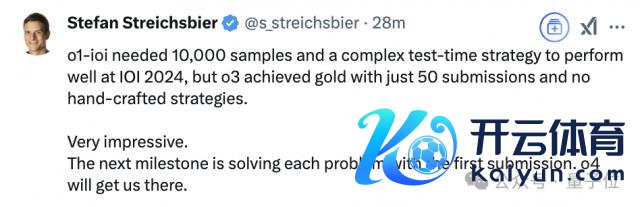
有网友贬抑到,o1-ioi 在 IOI 2024 上推崇出色,是因为它为每个问题生成了 10000 个候选解决决策,还用上了复杂的 test-time 策略;而 o3 在严格戒指下达到顶级选手水平,仅用了 50 次提交,且无东谈主工策略搅扰。
这就引出了 OpenAI 在论文中的一个高亮论断——
o3 的推崇,讲明了通过大限度端到端 RL(强化学习),无需依赖东谈主工联想的测试时推理策略,就能我方学会先写暴悉力解代码提高效果,再用其他要领交叉考证的策略。
网友满嘴喊着" impressive ":
下一个里程碑,是出现「单次提交就能处罚每个问题」的模子。
莽撞 OpenAI o4 会带来这个时刻。
现在,这篇名为《Competitive Programming with Large Reasoning Models》的回报论文还是挂在了 arXiv 上,文末可见纵贯车。
o 系三兄弟,竞赛编程输攻墨守
竞技编程,是评估大模子推理和编码智商的期许测试场景。
OpenAI 暗示,这篇论文的讨论主义,是探究在复杂编码和推理任务中,RL 对大模子所起到的作用。
讨论经过还对比了通用推理模子与范围特定系统的性能,探索晋升 AI 推贤惠商的灵验旅途。
参与讨论的推理模子共 3 个,均出自 OpenAI 自家家门,分辨是:
OpenAI o1
OpenAI o1-ioi
OpenAI o3
通用推理模子 o1
o1 是一个经过 RL 熟悉的大模子,用于处理复杂的推理任务。
通过 RL 熟悉,o1 能生成 CoT(chain-of-thought,想维链),其作用是想考息争决复杂问题,匡助模子识别和修订失误,将复杂任务明白为可护士的部分,并在要领失败时探索替代解决决策旅途。
除此以外,o1 还可调用外部用具考证代码。
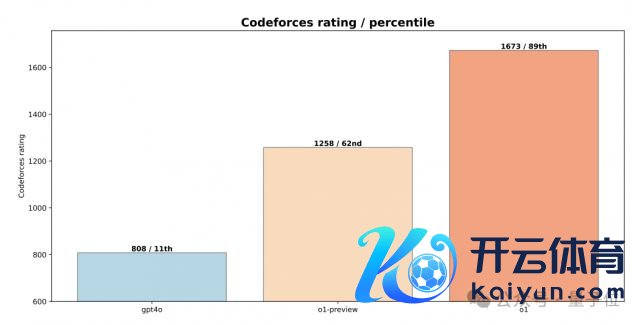
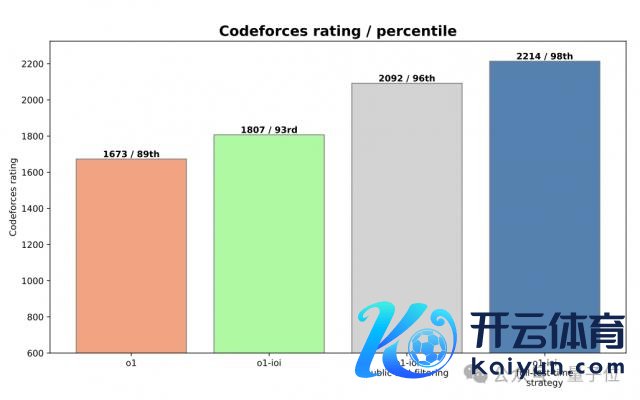
在 CodeForce 基准测试中,o1 拿下了 1673 分(89th percentile)。
比拟非推理模子(如 GPT-4o),和早期推理模子(如 o1-preview),o1 得益均有显耀晋升。
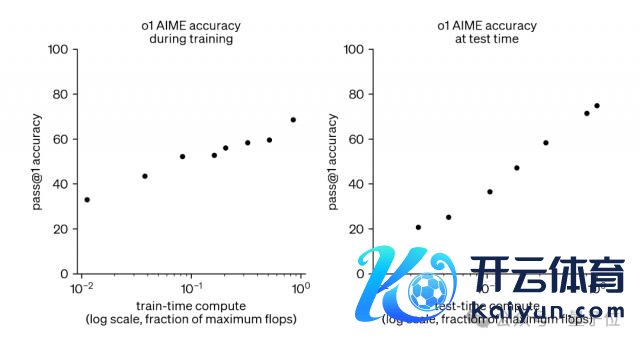
此外,讨论东谈主员在对 o1 进行开拓和评估的经过中,发现增多「RL 计较量」以及「test-time 推理计较量」两方面的职责,王人能抓续晋升模子性能。
如下图所示,彭胀 RL 熟悉和彭胀 test-time 推理均带来了显耀的收益。
针对性熟悉推理模子 o1-ioi
在发现增多「RL 计较量」以及「test-time 推理计较量」的广泛性后,OpenAI 团队在 o1 基础上进行针对性熟悉,得到 o1-ioi,场所直指 IOI 2024。
除了针对编码任务的抓续 RL 熟悉外,o1-ioi 还勾通了专为竞赛编程而联想的专用 test-time 推理策略(访佛 AlphaCode 的东谈主工联想的 test-time 推理策略)。
此经过第一步是彭胀 o1 的 RL 阶段,专注于编码任务。
通过将额外的熟悉计较专用于编程问题,团队增强了模子沟通、实施和调试更多波及的解决决策的智商。
具体如下:
从 o1 的 checkpoint 复原了 RL 熟悉。
特地强调了具有挑战性的编程问题,匡助模子翻新 C++ 生成和运转时查验。
勾引模子以 IOI 提交面孔生成输出。
这种对编码的额外柔柔,使 o1-ioi 能在推理时间编写和践诺 C++ 要领。
该模子通过迭代运转和优化解决决策来翻新其推贤惠商,从而增强了其编码息争决问题的智商。
o1-ioi 参与了东谈主类选手疏浚条款的 IOI 2024。
它有 10 个小时的时辰,来解决 6 个具有挑战性的算法问题,每个问题最多允许提交 50 次。
参赛时间,系统为每个问题生成了 10000 个候选解决决策,并使用 test-time 推理策略选了 50 个决策来提交——这里的 test-time 推理策略是,凭证 IOI 大家测试用例、模子生成测试用例和学习的评分函数上的推崇,来深信每个提交内容的优先级。
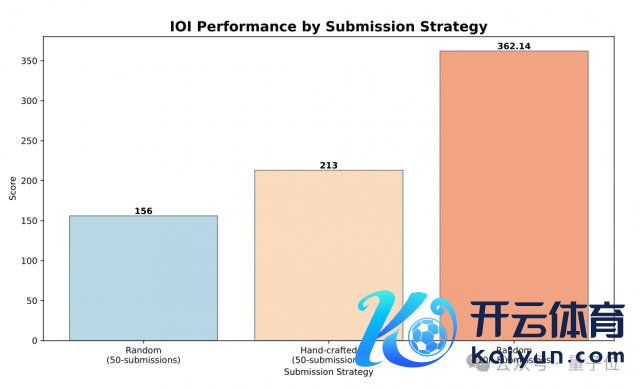
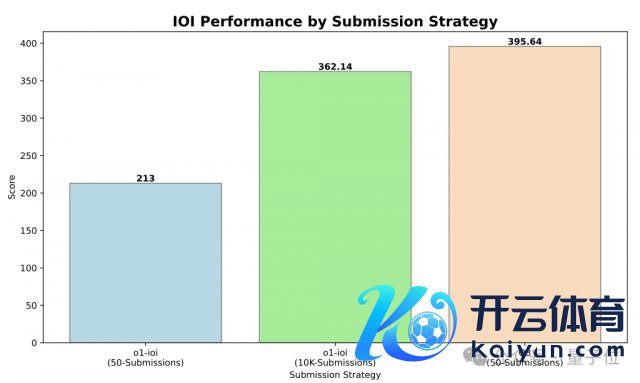
最终,o1-ioi 在 IOI 2024 获 213 分,名次前 49%。
在 CodeForces 基准测试上,o1-ioi 的评分达到 1807,超越了 93% 的竞争敌手。
论文中写谈,"这标明,在编码任务上的额外 RL 熟悉有了较着的翻新。"
然后,团队用一个粗浅的筛选条款来拒却任何未通过公开测试的解决决策时,评分高涨到 2092。
最终,在齐备的 test-time 推理策略推进下,o1-ioi 的评分飙升到 2214。
这些扫尾证实,特定范围的 RL 微调与高档禁受启发式相勾通,不错显耀提高有竞争力的编程扫尾。
讨论东谈主员暗示,o1-ioi 的推崇,讲明特定范围的 RL 微调与先进禁受策略,是不错晋升竞技编程得益的。
通用推理模子 o3
第三个参战的是 OpenAI 最新推理模子 o3。
基于 o1 和 o1-ioi 的推崇,OpenAI 团队探索了纯 RL 熟悉、不依赖东谈主工联想的 test-time 策略的局限性。
致使试图探索用 RL 进一步熟悉,该模子是否能够自主开拓和践诺我方的 test-time 推理策略
为此,团队取得了 o3 的早期 checkpoint 的走访权限,来评估竞赛编程。
参与 IOI 2024 竞赛时,o3 与 o1-ioi 相似严格遵命官方划定,每个问题最多允许提交 50 次。
与 o1-ioi 为每个子任务单独采样解决决策不同,团队在评估 o3 时,选择了不同的要领:
从包含原始问题的单个辅导中采样。

△o3 测试我方的解决决策
多提一句,插足 IOI 2024 的 o3 版块比插足 CodeForce 的 o3 版块更新,包含了额外的更新的熟整个据。
不外团队阐发了 IOI 2024 的测试集不包含在新的熟悉测试里。
在单个问题只可提交 50 次的戒指下,o3 在 IOI 2024 的最终得分是 395.64,超越了 IOI 2024 金牌门槛。
(IOI 2024 共产生 34 名金牌选手,金牌线为≥ 359.71)
而在 CodeForce 基准测试上,只是依靠进一步的 RL,o3 就获取了 2724 分的得益,力压 99.8% 的选手。
这个得益直逼东谈主类顶尖选手的水准!
值得贬抑的是,从得分 2214 的 o1-ioi(超越 98% 选手),到得分 2724 的 o3(超越 99.8% 选手),反应了推理模子在竞赛编程中的显耀晋升。
这标明 o3 能够以更高的可靠性,解决更平时的复杂算法问题,使其智商更接近 CodeForces 的顶级东谈主类竞争敌手。
更有预想的是,o3 在 CodeForce 参赛时间展现出了更三想此后行的想维链。
它不仅能写代码、践诺并考证,还会凭证反馈握住完善解法。
面临考证复杂的费劲,o3 在端到端 RL 时间,尽然学会了先写出暴力解法,再用最优算法的扫尾来交叉考证。
这种自主学习的考证机制,灵验提高了决策的可靠性。
综上,团队标明,o3 的性能优于 o1-ioi 的原因,不依赖于针对 IOI 的特定东谈主工联想的 test-time 策略。
相悖,o3 熟悉时间出现的复杂 test-time 时间——如用暴力解法来考证输出——成为了东谈主工设策略略的替代品,让 o3 不需要 o1-ioi 所需的手动联想聚类、禁受 pipeline 等需求。
且比东谈主工设策略略的性能高出不少。
软件工程任务推崇怎么?
除了竞赛编程,论文还在真确的软件工程任务上测试了 OpenAI 推理模子三兄弟的推崇。
团队主如若在 2 个数据集上测试了仨模子:
HackerRank Astra:用于评估大模子在跨域多文献表情问题上正确性和一致性的测试集
SWE-bench:用于评估和量度软件工程的基准测试和模子评估集,由普林斯顿大学 NLP 团队开拓
令东谈主惊喜的是,推贤惠商的增强对软件工程任务也有显耀晋升。
三兄弟不仅能在竞赛编程中直逼东谈主类顶尖选手,在真确的软件工程任务上也有亮眼推崇。
HackerRank Astra
HackerRank Astra 由 65 个面向表情的编码挑战构成,每个挑战王人是为了模拟真确的软件开拓任务而悉心联想的。
这些挑战涵盖了一系列框架,包括 React.js、Django 和 Node.js,允许获取构立功能和哄骗要领的现实造就。
该数据集的卓尔不群之处在于,它专注于评估反应内容开拓环境的复杂、多文献、长高下文场景中的问题解决手段。
与典型的竞争性编程数据集不同,HackerRank Astra 不提供公开的测试用例,这使 OpenAI 团队无法依赖东谈主工制作的测试时策略。
使用此数据集评估性能不错揭示推贤惠商是单独提高算法问题解决的告捷率,照旧彭胀到更内容的、与行业关系的编码任务。
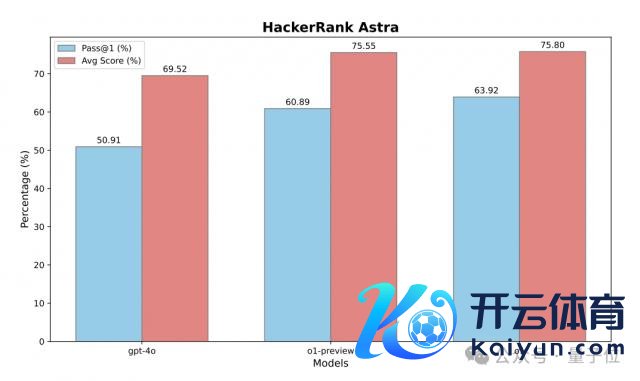
上图中的 pass@1,暗示初次尝试告捷完成任务的概率;平中分数,代表了通过的测试用例的平均比例。
扫尾骄横,与 GPT-4o 比拟,o1-preview 的 pass@1 提高了 9.98%,平中分提高了 6.03 分。
而 RL 进一步微调不错晋升 o1 的性能,其 pass@1 为 63.92%,比 o1-preview 提高了 3.03%;平均得分为 75.80。
这些方针讲明了 o1 增强的推理和符合性,使其能够灵验地处理复杂的、与行业关系的软件开拓任务。
SWE-bench
SWE-bench 由普林斯顿大学 NLP 团队开拓,而 SWE-bench Verified 是 OpenAI 的 preparedness 团队经过东谈主工考证的 SWE-bench 的子集。
它不错更可靠地评估 AI 模子解决内容软件问题的智商。
这组经过考证的 500 个任务,树立了 SWE-bench 的某些问题,如正确解决决策的不正确评分、未指定的问题报告以及过于具体的单位测试——这有助于确保基准测试准确地对模子功能进行分级。
整个模子王人尝试 5 次来生成候选 patch。
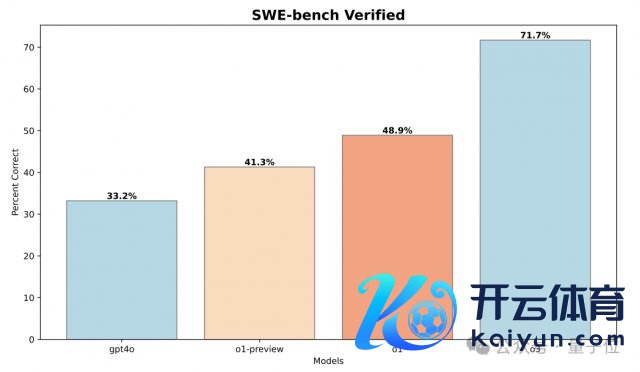
如上图所示,与 GPT-4o 比拟,o1-preview 在 SWE-bench 上的性能提高了 8.1%,展示了推贤惠商的明显跳动。
通过在熟悉时间哄骗额外的 RL 计较,o1 进一步翻新了 8.6%。
值得贬抑的是,熟悉计较资源比 o1 多得多的 o3,比 o1 翻新了 22.8%,"特地 impressive "。
这些扫尾暗示,推理模子对软件工程等内容任务,也有很大适用性和使用价值。
One More Thing
OpenAI 职工暗示,一张梗图不错很好地回想这篇论文。
略显缺憾的是,OpenAI 这篇新作天然挂在了 arXiv 上,但更像是回报而不管文——因为整篇论文没奈何浮现要领细节,光晒得益单了。
但其中所写真旧引起了网友的感触:
任何不错测量的东西,王人将得到改善。

论文纵贯车:
https://arxiv.org/pdf/2502.06807
参考蚁合:
[ 1https://x.com/arankomatsuzaki/status/1889522974467957033
[ 2 ] https://x.com/iScienceLuvr/status/1889517116816244995
[ 3 ] https://x.com/jennywxiao/status/1889517249033281631开yun体育网
